共计三台虚拟机分别为hadoop002(master,存放namenode),hadoop003(workers,datanode以及resourcemanage),hadoop004(workers.datanode,secondarynamenode)
1.搭建前的准备(三台虚拟机均已配置好java以及hadoop环境变量)
可以进行同步及执行命令的分发脚本,关闭防火墙,选定启动的hadoop的账号要能够做到与其他两台虚拟主机免密登录
2.配置hadoop002文件($HADOOP_HOME/etc/hadoop/)
hadoopenv.sh
1 export JAVA_HOME=/opt/module/jdk1.8.0_1812 export HADOOP_PID_DIR=/opt/module/hadoop-3.1.1/data/tmp/pids
core-site.xml
1 23 8 9 10hadoop.tmp.dir 4/opt/module/hadoop-3.1.1/data/tmp 5 6 711 fs.defaultFS 12hdfs://hadoop002:9000 13
hdfs-site.xml
1 23 6 7dfs.replication 43 58 11 12dfs.namenode.http-address 9hadoop002:50070 1013 dfs.namenode.secondary.http-address 14hadoop004:50090 15
yarn-site.xml(hadoop003上运行ResourceManager)
1 23 6 7 8yarn.resourcemanager.hostname 4hadoop003 59 yarn.nodemanager.aux-services 10mapreduce_shuffle 11
mapred-site.xml
1 23 mapreduce.framework.name 4yarn 5
workers
1 hadoop0022 hadoop0033 hadoop004
3.使用分发脚本同步$HADOOP_HOME/etc/hadoop下的配置文件
分发脚本请参考
在分发脚本同步前,要保证你的hadoop目录下没有存储临时文件的data目录(保险起见也删除logs文件夹),否则同步过去hadoop003与hadoop004的datanode会具有相同的storgeid与datanodeuuid.这样就会导致
启动datanode失败
执行同步命令
xsync.sh /opt/module/hadoop-3.1.1/etc/hadoop/
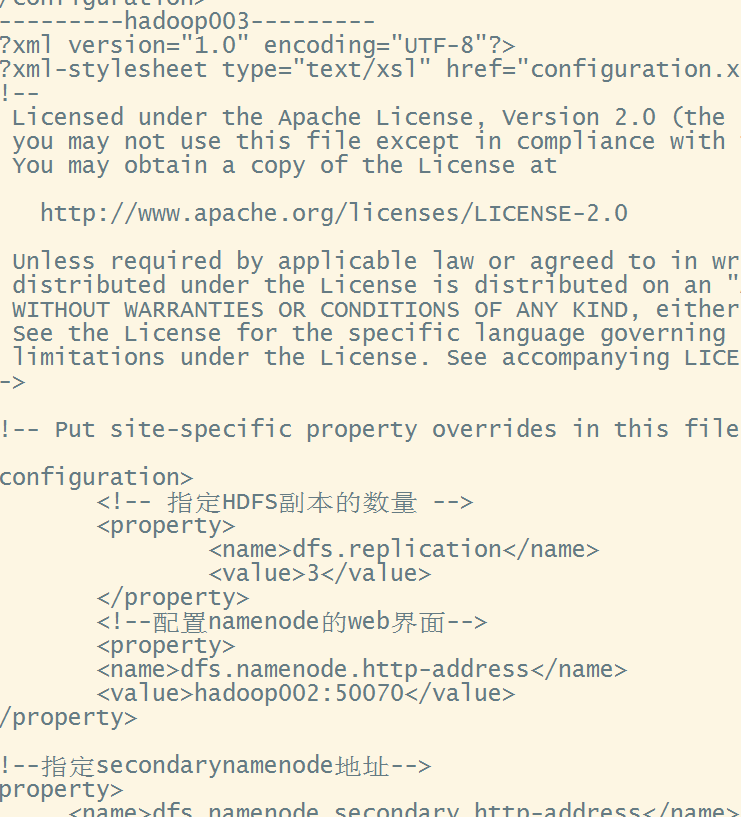
分发完毕后执行分发脚本进行查看
xcall.sh cat /opt/module/hadoop-3.1.1/etc/hadoop/core-site.xml
4.分步启动hadoop
如果你的虚拟机之前没有启动过hadoop,那么第一次启动时还要先进行格式化namenode(hadoop002),格式化namenode时如果出现了yes/no说明你之前的临时存储目录没有清理干净去检查下默认的/tmp是否有残留,没有在执行格式化命令,否则即使成功启动namenode仍然会有问题
hdfs namenode -format
之后在master上即hadoop002启动hdfs
start-dfs.sh
执行这个命令如果出现Permission denied (publickey,gssapi-keyex,gssapi-with-mic,password).是因为没有配置好ssh免密登录,请参考
启动成功后xcall.sh jps进行查看,确认三台虚拟机都有了datanode后在hadoop003上(可以在hadoop002上远程连接hadoop003然后启动)启动yarn
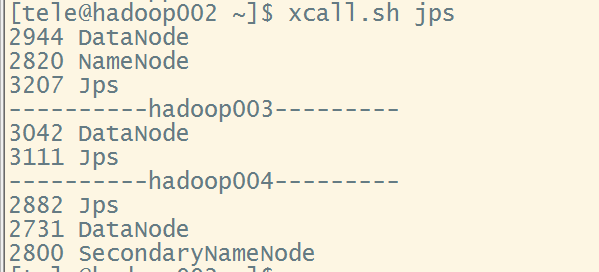
start-yarn.sh,之后在hadoop002上再次查看jps,这里需要注意的是ResourceManager配置在哪台机器上就要在哪台机器上启动yarn
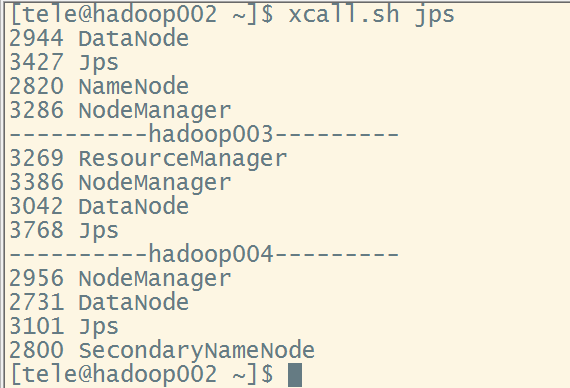
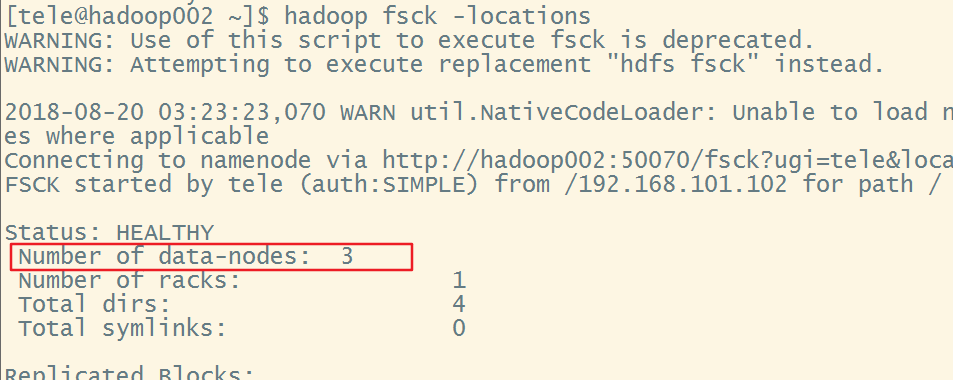
此时已经启动完成,可以执行以下命令查看datanode是否配置正确,否则即使datanode启动了,也不是从属于我们配置的namenode
hadoop fsck -locations(但这个命令并不是判断datanode是否启动的依据,还是要看jps)
再次重申,一定要关闭防火墙如果你只是配置了开放防火墙的某些端口,后面测试文件上传的时候仍然会有问题
5.文件上传测试
创建文件夹
hadoop fs -mkdir -p /usr/tele创建完成后可在hadoop002:50070观察到效果web页面无法打开请参考
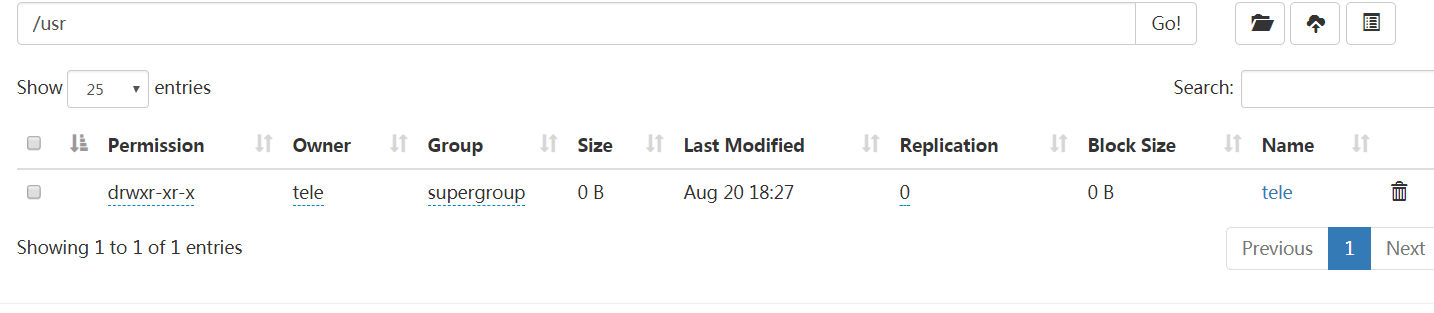
上传文件
hadoop fs -put /opt/software/jdk-8u181-linux-x64.tar.gz /usr/tele
(如果上传失败,请检查文件夹权限,尽量使用普通账号启动hadoop)

如果发现Replication与Availability不一致,请参考
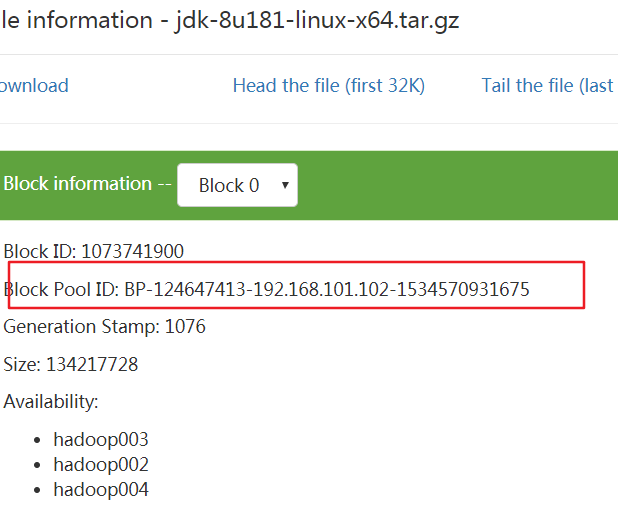
接下来进入hdfds实际在linux上的存储路径,一会要根据Block Pool ID寻找存储的文件,进入以下目录
/opt/module/hadoop-3.1.1/data/tmp/dfs/data/current/BP-124647413-192.168.101.102-1534570931675/current/finalized/subdir0/subdir0

可以看到上传的jdk1.8的压缩包被分成了两个block,接下来对文件进行合并
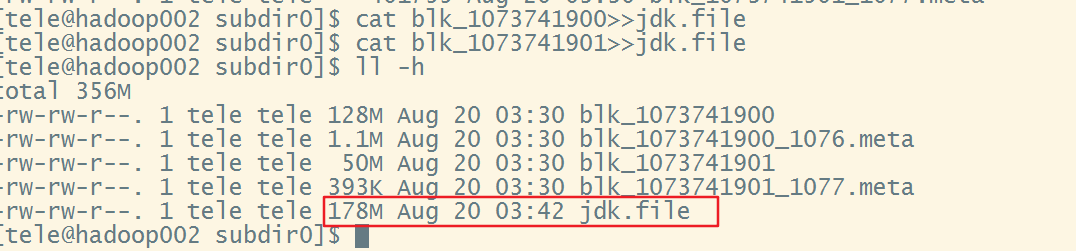
解压这个jdk.file就会得到我们上传的jdk压缩包了tar -zxvf jdk.file
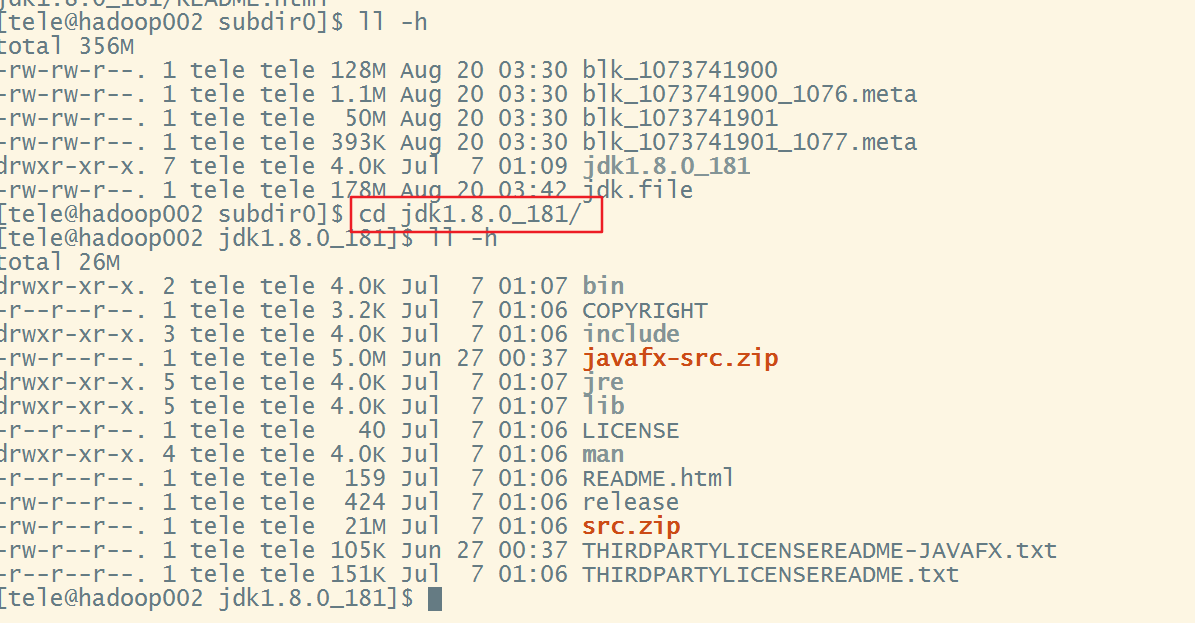
当然也可以使用hadoop fs -get命令进行下载,接下来进入hadoop003与hadoop004分别查看是否有我们的备份

hadoop004的图不再贴了,同样也有备份,到这搭建与测试全部完成了
6.停止
先在hadoop003停止yarn,jps后在hadoop002停止datanode,由于在开头配置hadoop-env.sh时指定了pid的存储目录,所以不用担心pid文件被清理掉
7.总结
①尽量不要使用stop-all.start-all.sh来操作集群,停止与启动都要分步操作,请参考
②datanode与namenode的联系靠的是datanode的clusterID,从属于同一namenode的datanode具有相同的clusterID,当然不同的datanode其storgeid与datanodeuuid是不同的,如果你在启动的过程中发现总是只有一个datanode可以启动,那么你就要考虑datanode的id冲突问题了
③必须在配置ResourceManager的机器上启动yarn
④防火墙必须关闭,只开放部分端口会导致写入副本时报错java.io.IOException: Got error, status=ERROR, status message , ack with firstBadLink as 192.168.101.103:9866查看datanode的日志会有java.net.NoRouteToHostException: No route to host等问题
⑤yarn-site.xml与mapred.xml中尽量不要使用中文注释否则启动的时候会有一个java.lang.RuntimeException: com.ctc.wstx.exc.WstxIOException: Invalid UTF-8 start byte 0xb5 (at char #672, byte #20
⑥修改配置文件前要把hadoop停掉,然后才会生效(个别文件例外,但还是建议停掉hadoop再进行修改)
⑦workers文件对应2,x的slaves,从奴隶变成了工人
⑧3.x中yarn-env.sh与mapred-env.sh已经不再需要配置export JAVA_HOME